




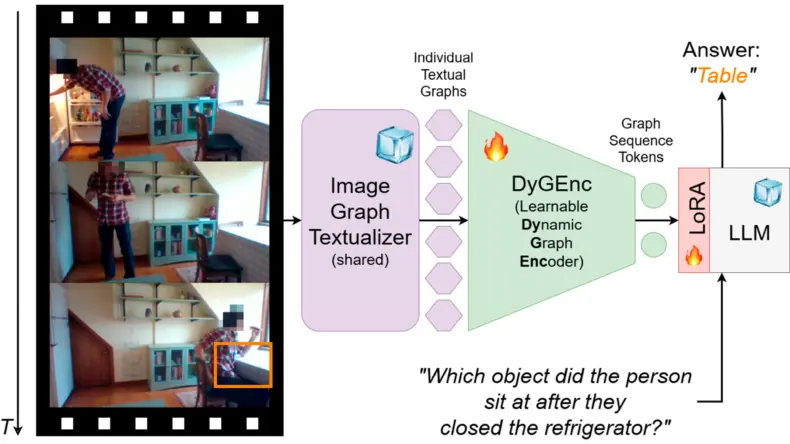
Суть технологии заключается в преобразовании видеоряда в динамический граф событий. Объекты становятся вершинами, а их действия и связи – ребрами. Этот структурированный «скелет» сцены подается в языковую модель, что позволяет ей точно отвечать на сложные вопросы о последовательности действий и предугадывать следующий шаг.
Эффективность алгоритма была подтверждена на международных тестах. На бенчмарке STAR точность прогнозирования взаимодействий достигла 99%, а предсказание следующего действия – 97%. В более сложном испытании AGQA, включавшем 2,27 млн вопросов, точность понимания открытых запросов выросла с 54% до 93% после применения нового метода.
Разработчики успешно интегрировали алгоритм в реального робота. Мобильная платформа с манипулятором выполняла команды на русском языке (например, «подъехать к столу и взять предмет»), анализируя видеопоток с камер в реальном времени. Система продемонстрировала высокую устойчивость: даже при намеренном добавлении шумов (удалении связей или замене слов синонимами) точность ответов оставалась выше 90%. Код проекта уже доступен на GitHub для использования научным сообществом.


















